Automatización Inteligente: Testing Funcional con IA.
Este documento es un extracto de la idea principal presentada en el trabajo final de la defensa del Diploma en Gerencia de Calidad y Testing de Software 2024, impartido por el CES (Centro de Ensayos de Software) del Programa de Educación Permanente de la Facultad de Ingeniería de la UDELAR.
El trabajo original del cual deriva este extracto es de la autoría de Valentina Prado, Cristian Silvera.
Explica los conceptos, procesos y beneficios de integrar Inteligencia Artificial en el testing funcional mediante un sistema de automatización inteligente con capacidades de autocorrección.
Para facilitar su comprensión, realicé una simplificación del trabajo realizado. Esta abstracción pretende explicar el ciclo de vida de los tres componentes fundamentales que participan del sistema.
Planteo del sistema.
La idea fundamental de este trabajo es diseñar un sistema de automatización con capacidades de autocorrección (Self-Healing), compuesto por tres elementos principales:
- Test Automatizado:
- Ejecuta pruebas sobre una aplicación (por ejemplo, una calculadora Android).
- Monitorea los logs de la aplicación en busca de errores que puedan ocurrir debido a cambios en los selectores o la interfaz.
- Modelo LLM-RAG (Language Model + Retrieval-Augmented Generation):
- Recibe consultas derivadas de los logs con detalles de errores.
- Procesa y analiza los datos mediante vectorización y un motor de consulta, generando una respuesta enriquecida, como selectores actualizados y funcionales.
- Aplicación:
- Actúa como el entorno bajo prueba.
- Proporciona los datos (logs) que desencadenan la retroalimentación en el sistema.
Flujo del Sistema:
- El Test Automatizado ejecuta un script y monitorea los logs de la aplicación.
- Ante un error, el Test genera una consulta con los detalles del problema y la envía al Modelo LLM-RAG.
- El Modelo procesa la consulta, busca en su base de datos vectorizada y devuelve una respuesta con información actualizada (nuevos selectores).
- El Test aplica la información para corregir el error y re ejecutar la prueba (Self-Healing).
- Si la corrección falla después de varios intentos, el sistema registra los detalles del error para una intervención manual.
Propósito:
El objetivo del sistema es reducir la dependencia de la intervención humana en la automatización de pruebas, permitiendo que las pruebas puedan adaptarse automáticamente a cambios en la aplicación, mejorando así la eficiencia y confiabilidad en el proceso de testing.
Definiciones
Definición de Self-Healing
Self-Healing en el contexto de automatización de pruebas se refiere a la capacidad de una prueba automatizada para recuperarse automáticamente de fallos temporales o intermitentes sin intervención manual. Esto incluye la capacidad de manejar situaciones donde los elementos de la interfaz de usuario (UI) pueden no estar disponibles inmediatamente debido a problemas de sincronización, carga o cambios en la estructura de la UI.
Características de un Test con Enfoque Self-Healing
Para implementar un enfoque Self-Healing en tus pruebas automatizadas, estas deben incluir las siguientes características:
- Múltiples Estrategias de Localización:
- Utilizar varios selectores para localizar un elemento. Si un selector falla, intentar con otro.
- Ejemplo: Usar
accessibility id,resource id,xpath,css selector, etc.
- Reintentos Automáticos:
- Implementar lógica de reintento para intentar encontrar y interactuar con los elementos varias veces antes de fallar.
- Ejemplo: Reintentar hasta 3 veces con un intervalo de espera entre intentos.
- Manejo de Excepciones:
- Capturar y manejar excepciones de manera que la prueba pueda continuar incluso si un paso falla temporalmente.
- Ejemplo: Si un elemento no se encuentra, capturar la excepción y reintentar.
- Condiciones de Espera Personalizadas:
- Definir condiciones de espera personalizadas para manejar situaciones específicas de la aplicación.
- Ejemplo: Esperar a que un elemento desaparezca antes de continuar.
- Captura de Pantalla en Fallos:
- Tomar capturas de pantalla en caso de fallos para facilitar el diagnóstico.
- Ejemplo: Guardar una captura de pantalla cada vez que un paso falla.
- Logs Detallados:
- Agregar logs detallados para entender mejor qué está sucediendo durante la ejecución de la prueba.
- Ejemplo: Loggear cada intento de reintento y cualquier excepción capturada.
- Verificación del Estado de la Aplicación:
- Verificar el estado de la aplicación antes de realizar una acción para asegurarse de que está en el estado esperado.
- Ejemplo: Verificar que ciertos elementos están visibles o que ciertos textos están presentes.
- Uso de Variables de Entorno:
- Utilizar variables de entorno para configurar parámetros como el número de reintentos y el tiempo de espera.
- Ejemplo: Configurar el número de reintentos y el tiempo de espera a través de variables de entorno.
Definición de LLM-RAG
- LLM:
- Large Language Model: Se refiere a modelos de lenguaje de gran tamaño que están diseñados para entender y generar texto en lenguaje natural. Estos modelos son entrenados con grandes cantidades de datos textuales y pueden realizar una variedad de tareas, como responder preguntas, traducir texto, resumir documentos y más.
- RAG:
- Retrieval-Augmented Generation: Es una técnica que combina la recuperación de información (retrieval) con la generación de texto. En este enfoque, un modelo de lenguaje utiliza información recuperada de una base de datos o un índice de documentos para mejorar la calidad y la precisión de las respuestas generadas. Esto es útil cuando se necesita información específica y actualizada que no está necesariamente incluida en el entrenamiento del modelo de lenguaje.
Diagrama de un RAG:
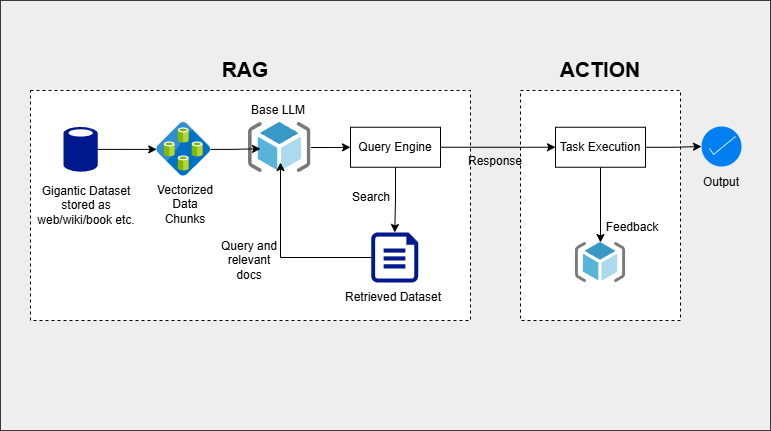
1. RAG (Retrieval-Augmented Generation):
Este bloque se centra en buscar información relevante de un conjunto de datos masivo y contextualizarla antes de responder a la consulta.
- Gigantic Dataset:
- Es una colección masiva de datos, que puede estar formada por sitios web, wikis, libros u otras fuentes. Estos datos son procesados y transformados en representaciones útiles.
- Vectorized Data Chunks:
- Los datos originales se dividen en fragmentos pequeños y se convierten en vectores (la vectorización es el proceso de transformar datos textuales en una representación numérica que los algoritmos de machine learning pueden procesar.) mediante un modelo de machine learning. Esto permite que los datos puedan ser buscados y relacionados de manera eficiente basándose en similitudes.
- Base LLM (Large Language Model):
- El modelo de lenguaje (LLM) sirve como la base para interpretar la consulta inicial del usuario. Genera una consulta enriquecida que combina contexto y relevancia.
- Query Engine:
- Esta componente busca en el conjunto de datos vectorizados usando la consulta generada por el LLM. Su objetivo es recuperar los fragmentos de datos más relevantes para la pregunta inicial.
- Retrieved Dataset:
- Los documentos o datos relevantes recuperados se combinan y se proporcionan como contexto adicional para que el LLM pueda generar una respuesta más precisa.
2. ACTION:
Esta parte del modelo se centra en actuar sobre la información generada para ejecutar tareas concretas.
- Response (Respuesta):
- El LLM utiliza el contexto proporcionado por los documentos recuperados para generar una respuesta precisa o un plan de acción.
- Task Execution:
- En esta etapa, la respuesta del modelo no solo es textual, sino que puede incluir la ejecución de tareas específicas (por ejemplo, invocar APIs, realizar cálculos, ejecutar scripts, etc.).
- Feedback:
- Se genera un ciclo de retroalimentación en el que los resultados obtenidos de la ejecución se evalúan y, si es necesario, se ajusta la respuesta inicial para mejorar el resultado.
- Output:
- Finalmente, se entrega un resultado validado y optimizado como salida final para el usuario.
Propósito y Ventajas del Modelo
- Combina búsqueda y generación: El modelo aprovecha datos externos masivos para aumentar la precisión y contextualización de las respuestas generadas por el LLM.
- Capacidad de ejecución: No se limita a responder preguntas, sino que también ejecuta tareas con base en las instrucciones.
- Adaptabilidad: Aprende y mejora continuamente gracias al ciclo de retroalimentación.
Ejemplo detallado de la integración.
En el siguiente diagrama se integra el modelo RAG que contiene el script o sistema de actualización y sincronización de los insumos de recuperación del test (para este ejemplo los selectores de los componente de una aplicación Android) con la ACTION que maneja las tareas que monitorean y disparan la consulta en caso de error que acciona el script de actualización de la información que utiliza el modelo para dar una respuesta que se comunica con el test y proporciona los componentes necesarios para su auto-reparación.
Diagrama integración:
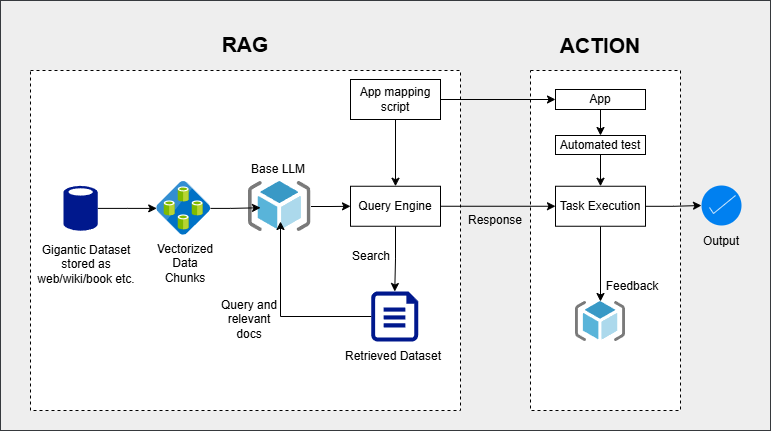
Explicación de la ubicación de los componentes en el diagrama:
- Aplicación:
- Colocada antes de "Task Execution" en la sección ACTION.
- Rol: Es el sistema bajo prueba (por ejemplo, una calculadora Android) que genera logs (retroalimentación) para el modelo y ejecuta las acciones probadas por el test automatizado.
- Conexiones:
- Recibe comandos desde "Task Execution".
- Genera logs que se usan para identificar problemas mediante el "Base LLM".
- Test Automatizado:
- Posicionado entre "Task Execution" y la Aplicación.
- Rol: Ejecuta pruebas sobre la aplicación, monitorea logs en busca de errores y comunica las consultas al modelo RAG.
- Conexiones:
- Obtiene comandos de "Task Execution".
- En caso de errores, envía los logs al "Query Engine" del RAG para análisis.
- Script de Mapeo de Selectores:
- Localizado dentro de la "Query Engine" del modelo RAG.
- Rol: Procesa las consultas y genera una lista de selectores actualizados que corrigen problemas detectados en la aplicación.
- Conexiones:
- Toma la entrada del "Base LLM".
- Entrega la salida (nuevos selectores) al "Task Execution".
Flujo Integrado:
- El Test Automatizado ejecuta scripts sobre la Aplicación y monitorea los logs.
- Si se detecta un error, los logs se convierten en una consulta para el Base LLM.
- El Query Engine procesa la consulta y ejecuta el Script de Mapeo de Selectores para generar una lista de selectores actualizados.
- Los nuevos selectores se envían al Task Execution, que los utiliza para ajustar el Test Automatizado.
- El Test Automatizado re ejecuta las pruebas con los selectores actualizados.
- Si las pruebas son exitosas, no se realizan nuevas consultas al modelo. Si persisten los errores, el flujo se repite hasta un límite predefinido, tras el cual se registra el problema para intervención manual.
Diagrama UML.
Componentes:
- Test Automatizado (Actor principal que inicia el flujo).
- Aplicación (App Android) (Elemento bajo prueba).
- Modelo LLM-RAG (Procesador de consultas y generador de respuestas).
- Base de Datos Vectorizada (Almacenamiento de información para el modelo).
Flujo (Secuencia Simplificada):
- Inicio del Test Automatizado:
- Ejecuta scripts para validar funcionalidades de la aplicación.
- Monitorea logs en busca de errores.
- Error Detectado:
- El test genera una consulta detallada con los logs del error.
- Envía la consulta al Modelo LLM-RAG.
- Modelo LLM-RAG Procesa la Consulta:
- Accede a la Base de Datos Vectorizada.
- Enriquecer la consulta con contexto adicional usando la Base LLM.
- Genera una respuesta con los selectores corregidos o sugeridos.
- Respuesta al Test:
- El modelo devuelve la respuesta al test.
- El test aplica el método de Self-Healing y se vuelve a ejecutar.
- Monitoreo de Resultados:
- Si el test es exitoso, finaliza el proceso.
- Si falla, el ciclo se repite (máximo X intentos).
- Si no se resuelve, se guarda un registro para el debugging manual.
Diagrama UML en texto PlantUML.
@startuml
actor "Test Automatizado" as Tester
participant "Aplicación (App Android)" as App
participant "Modelo LLM-RAG" as Model
participant "Base de Datos Vectorizada" as DB
Tester -> App: Ejecuta scripts
App --> Tester: Logs (Errores o Exitosos)
alt Error Detectado
Tester -> Model: Enviar consulta detallada (Logs del error)
Model -> DB: Consultar datos relevantes
DB --> Model: Respuesta con datos enriquecidos
Model --> Tester: Respuesta con selectores actualizados
Tester -> App: Aplicar Self-Healing y volver a ejecutar
end
alt Test Exitoso
Tester -> Tester: Finaliza el proceso
end
alt Test Falla tras X intentos
Tester -> Tester: Registrar detalles para debugging manual
end
@enduml
Resumen de la interacción.
Con base en la idea planteada, he diseñado un esquema conceptual para integrar un flujo con Self-Healing Testing basado en un modelo LLM-RAG. Este flujo conecta tres componentes principales: el test automatizado, la aplicación (app), y el modelo LLM-RAG. El proceso incluye detección de errores, consultas automatizadas al modelo y auto-corrección mediante sincronización de selectores.
Esquema del Sistema.
Componentes Principales:
- Test Automatizado (Automation Test):
- Ejecuta scripts para validar la funcionalidad de la aplicación.
- Monitorea los logs en tiempo real.
- Dispara una consulta al modelo LLM-RAG en caso de encontrar un error.
- Aplicación (App Android, ejemplo Calculadora):
- La aplicación bajo prueba, que contiene los selectores dinámicos que pueden romperse durante los cambios en el sistema.
- Modelo LLM-RAG (Adaptado):
- Realiza procesamiento basado en consultas enriquecidas.
- Genera selectores actualizados y ordenados por funcionalidad.
- Integra un motor de búsqueda en datos vectorizados (Query Engine).
- Devuelve una respuesta al test automatizado para ejecutar el self-healing.
- Script de actualización y sincronización de componentes:
- Realiza un mapeo de los componentes afectados, según la información de los logs (el error es la consulta que dispara la acción de actualización y sincronismo).
- Almacena la información mapeada en el modelo para que sea procesada y preparada para su consulta.
Flujo Detallado:
1. Ejecución Inicial del Test Automatizado:
- El test automatizado interactúa con la aplicación utilizando selectores conocidos.
- Los logs del test son monitoreados para detectar errores.
2. Detección de Error y Disparo de Consulta:
- Si el test falla debido a un problema con los selectores (por ejemplo, selector ausente o incorrecto):
- Los logs son analizados automáticamente.
- Se genera una consulta estructurada con el detalle del error (ej., tipo de error, selector roto, contexto funcional).
- Se da la orden para el mapeo de la aplicación, actualizando y sincronizando la información en el modelo.
3. Envío de Consulta al Modelo LLM-RAG:
- La consulta es enviada al modelo LLM-RAG, que sigue estos pasos:
- Base de Datos Vectorizada: Los datos sobre la aplicación y sus selectores son almacenados como chunks vectorizados para búsquedas eficientes(esto es posible mediante el script de actualización y sincronía que envía datos).
- Base LLM: Procesa la consulta y genera una versión enriquecida con contexto adicional.
- Query Engine: Busca en los datos vectorizados los selectores relevantes y actualizados.
- Respuesta Generada: Devuelve una lista priorizada de selectores corregidos o alternativos basados en la funcionalidad (en el anexo, se detalla como estos datos son recorridos por una estructura de control).
4. Self-Healing del Test:
- El test automatizado recibe la respuesta del modelo mientras está en ejecución debido a las técnicas de self-healing, que actualizan los selectores dinámicamente.
- El test se reintenta recuperar automáticamente con los nuevos selectores.
5. Monitoreo de Logs (Ciclo de Retroalimentación):
- Si el test es exitoso:
- El flujo se detiene y la ejecución continúa normalmente.
- Almacenando las métricas en el histórico de ejecuciones para Feedback del modelo (se genera un ciclo de retroalimentación en el que los resultados obtenidos de la ejecución se evalúan y, si es necesario, se ajusta la respuesta inicial para mejorar el resultado.)
- Si falla nuevamente:
- Se genera una nueva consulta al modelo, intentando un máximo de X intentos.
- Si no se resuelve tras múltiples intentos:, los detalles del error se almacenan para facilitar el debugging manual.
- Feedback del modelo.
ANEXO.
Ejemplo de Implementación de Self-Healing:
El siguiente código corresponde a la automatización móvil, de la Calculadora en el sistema operativo Android. Donde se implementa Self-Healing de manera efectiva.
Link a repositorio:
Aquí hay un análisis detallado de cómo lo realizamos:
1. Múltiples Estrategias de Localización
El método getElementWithBackupSelectors intenta localizar un elemento utilizando múltiples selectores. Si un selector falla, intenta con el siguiente. Esto es una forma de Self-Healing porque permite que la prueba continúe incluso si el primer selector no funciona.
private async getElementWithBackupSelectors(selectors: string[]) {
let lastError: Error | null = null;
for (let selector of selectors) {
try {
const element = await $(selector); // Espera el elemento
if (await element.isDisplayed()) {
return element;
}
} catch (error) {
lastError = error; // Almacena el último error para reportarlo
}
}
// Si ninguno de los selectores funciona, lanzar el último error encontrado
if (lastError) throw lastError;
throw new Error('No se pudo localizar el elemento con ninguno de los selectores.');
}
2. Reintentos Automáticos
La función retry implementa una lógica de reintento con backoff exponencial. Esto significa que si un intento falla, espera un tiempo antes de reintentar, y el tiempo de espera aumenta exponencialmente con cada reintento. Esto es útil para manejar situaciones donde los elementos pueden no estar disponibles inmediatamente debido a problemas de sincronización o carga.
private async retry(fn, retries = 3, delay = 1000) {
let attempt = 0;
while (attempt < retries) {
try {
return await fn();
} catch (error) {
if (attempt === retries - 1) {
throw error;
}
const nextDelay = delay * Math.pow(2, attempt); // Backoff exponencial
console.log(`Intento ${attempt + 1} fallido. Reintentando en ${nextDelay} ms...`);
await new Promise(resolve => setTimeout(resolve, nextDelay)); // Espera con backoff
attempt++;
}
}
}
3. Manejo de Excepciones
El método tryClickButton intenta hacer clic en un botón y maneja las excepciones. Si el botón no se encuentra, intenta buscar un localizador alternativo. Esto es otra forma de Self-Healing porque permite que la prueba continúe incluso si el primer intento de hacer clic falla.
private async tryClickButton(btn) {
try {
// Espera hasta que el botón sea visible
await btn.waitForDisplayed({ timeout: 5000 });
await btn.click(); // Realiza el clic
} catch (error) {
// Si el botón no se encuentra, intentamos buscar un localizador alternativo
console.log(`Fallo al encontrar el botón con el localizador inicial. Intentando con un alternativo.`);
await this.retry(() => btn.waitForDisplayed({ timeout: 5000 }));
await btn.click();
}
}
4. Uso de Múltiples Estrategias en los Botones
Los botones btnNumero, btnMas y btnIgual utilizan múltiples estrategias de localización, lo que aumenta la robustez de la prueba.
get btnNumero() {
return (numeroDeseado: string) => this.getElementWithBackupSelectors([
`~${numeroDeseado}`, // Usar ~ correctamente sin las plantillas de cadena
`android=new UiSelector().description("${numeroDeseado}")`, // Usar descripción como backup
]);
}
get btnMas() {
return this.getElementWithBackupSelectors([
'~máss',
'android=new UiSelector().description("sumar")',
'android=new UiSelector().resourceId("com.google.android.calculator:id/btn_plus")',
'~más'
]);
}
get btnIgual() {
return this.getElementWithBackupSelectors([
'~igual a',
'android=new UiSelector().description("igual")',
'android=new UiSelector().resourceId("com.google.android.calculator:id/btn_eq")',
]);
}
Nota: Sí bien el código implementa Self-Healing de manera efectiva mediante el uso de múltiples estrategias de localización, reintentos automáticos con backoff exponencial y manejo de excepciones. Esto hace que la automatización sea más robusta y capaz de recuperarse de fallos temporales. Es un ejemplo que está implementado localmente y no implementa la lógica que conecta con el modelo LLM-RAG.
Conclusión
El uso de Inteligencia Artificial y técnicas de Self-Healing en la automatización del testing funcional optimiza recursos, mejora la resiliencia y reduce la dependencia de actualizaciones manuales. Este enfoque permite adaptarse a cambios en las aplicaciones y eleva la calidad de las pruebas, garantizando además la trazabilidad mediante el registro histórico de información. En un entorno ágil, estas herramientas representan un paso clave hacia sistemas de pruebas más eficientes e inteligentes.
Bibliografía
¿Qué es la automatización inteligente? (2023, mayo 16). Ibm.com.
https://www.ibm.com/es-es/topics/intelligent-automation
¿Qué es la Inteligencia Artificial (IA)? (2024, junio 14). Ibm.com.
https://www.ibm.com/mx-es/topics/artificial-intelligence
Rojas, G. I. (2023, febrero 9). Inteligencia Artificial al servicio del Testing.
Linkedin.com.
https://www.linkedin.com/pulse/inteligencia-artificial-al-servicio-del-test
ing-gustavo-inzunza-rojas/
Schmidt, R. (2023, junio 8). El papel de la IA en las pruebas de software.
Appmaster.io; AppMaster.
https://appmaster.io/es/blog/ai-en-pruebas-de-software
Testing automatizado de software basado en IA. (s/f). CaixaBank Tech.
Recuperado el 12 de noviembre de 2024, de
https://www.caixabanktech.com/es/blogs/testing-automatizado-de-software-basado-en-ia/
(S/f). Amazon.com. Recuperado el 12 de noviembre de 2024, de
https://aws.amazon.com/es/what-is/intelligent-automation/
Introduction. (s/f). Continue.dev. Recuperado el 18 de noviembre de 2024, de https://docs.continue.dev/
Bienvenue to Mistral AI documentation. (s/f). Mistral.Ai. Recuperado el 18 de noviembre de 2024, de https://docs.mistral.ai/
library. (n.d.). Ollama.com. Retrieved November 18, 2024, from https://ollama.com/library
llama3.1. (s/f). Ollama.com. Recuperado el 19 de noviembre de 2024, de https://ollama.com/library/llama3.1
Visual testing. (n.d.). Webdriver.Io. Retrieved November 18, 2024, from https://webdriver.io/docs/visual-testing/
OCR testing. (s/f). Webdriver.Io. Recuperado el 19 de noviembre de 2024, de https://webdriver.io/docs/ocr-testing/ocr-testing/
Applitools eyes documentation. (s/f). Applitools. Recuperado el 1 de diciembre de 2024, de https://applitools.com/docs/index.html
(S/f). Amazon.com. Recuperado el 2 de diciembre de 2024, de https://aws.amazon.com/what-is/retrieval-augmented-generation/
Cómo utilizar tus propios documentos con LLMs - Conceptos fundamentales de sistemas RAG
- YouTube
. (s/f). Youtu.Be. Recuperado el 3 de diciembre de 2024, de